

A significant amount of software architecture revolves around considering user and system testing requirements. These requirements fundamentally shape how you structure your deployment pipeline and the needed environments. The more resilient your software needs to be, the more layers you will add to your deployment pipeline. However, that also drives up complexity and cost. As the architect, finding the balance between these competing interests is your job. Here are some examples of environments I have encountered, what needs they fulfill, and where they might be used.
YOLO
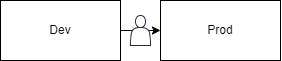
Let’s start with the most simple pipeline, also known as “YOLO,” in my mind. It’s a simple and cost-effective option but sacrifices a significant amount of robustness.
The Dev environment is the developer’s machine where they maintain the code. The Prod environment is the production environment that all users will access. In the YOLO setup, the production environment gets deployed when a user triggers a release from the main source control branch. Automating the deployment to Prod in this style pipeline is not recommended.
With this setup, the risk of encountering bugs and deployment issues is quite high for each release. It’s unsuitable for many production use cases, but it can work when an organization primarily uses the system internally, is non-critical, and changes are infrequent. It could also be a starting point for systems currently lacking controls.
Advantages
- Simple setup
- Low cost
- Minimal maintenance
Disadvantages
- No testing
- High risk of bugs
- Reduced uptime
- Hotfixes difficult
- Little to no automation
Use Cases
- Non-critical internal business software
- Starting point for an existing system
- Systems with very few updates
Basic Testing

Now, we will level up and introduce some additional environments to enhance robustness, catch issues, and implement approval gates. The first one on the list is a QA environment. This environment aims to allow developers and QA engineers to test the code before it goes live in production. It also serves as an initial check against any deployment problems.
In this pipeline, the QA environment gets automatically updated whenever new code is pushed into the main branch. Then, when the release is ready and approved, someone initiates the deployment process to push it into production. At this level, you should use Infrastructure as Code to make your environment changes.
This basic testing pipeline significantly improves system robustness and overall quality. Both the code and deployment process can now undergo testing, and the system’s complexity remains relatively low. Following the 80/20 rule, this pipeline example represents the 20% of effort that brings about 80% of the value.
However, we still have a few challenges with this setup. The most notable one is when a hotfix is required, but QA has other partially completed features in the main branch. In this scenario, we can’t simply deploy the hotfix right away. Instead, we have to go through reverting the code, resolving the hotfix issue, and deploying it. Afterward, we must return the other features to the main branch and redeploy them to QA. If the hotfix needs further fine-tuning, we might find ourselves stuck in a loop, holding up the development of other features. Addressing these challenges is essential to maintain a smooth and efficient workflow.
Advantages
- Simple setup
- Most bugs can be found before production
- Low maintenance
- Improved uptime
- Some automation
Disadvantages
- Bugs with production data may persist
- Hotfixes difficult
- Lacks advanced testing
Use Cases
- Systems with few updates
- Tolerance for delayed hotfixes
Basic Testing with Hotfixes
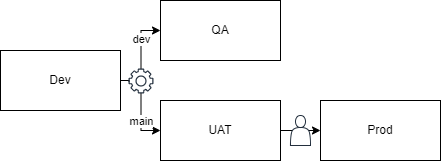
Now let’s tackle the hotfix problem with the next level of environments. This setup is ideal for systems that require more frequent updates and have less tolerance for bugs and downtime.
We’ll introduce a dev branch that will automatically deploy to our QA environment. This is where all the new system features will go as they’re being developed. Your QA environment will be buggy and volatile. The QA environment is where most issues should be identified. It’s also an excellent time to start acceptance testing, although more extensive testing will be conducted later.
Once the features are nearly ready, the dev branch is merged into the main branch and automatically deployed to our new User Acceptance Testing (UAT) environment. UAT is where the product manager, stakeholders, and other business personnel determine whether the new features are ready for production. Some bugs may surface during this stage, but that should be rare and minimal.
This pipeline setup resolves most of our hotfix issues because new features should only make their way to the main branch and the UAT environment when they’re almost ready. This means that the main branch is typically available for hotfixes. Hotfixes become problematic only when they coincide with the time when features are also nearing completion. However, with careful planning, this window should be brief, and if needed, the release can be used to deploy the hotfix.
By implementing this pipeline structure, we can better manage our deployment process and address hotfixes more efficiently. There are only two manual decision points or approval gates here. The first is when to merge code from the develop branch into the main branch. This merge is performed when the new code is feature-complete and production ready. The second manual decision is for the business decision-makers to sign off on the changes in UAT. This is the decision point where it is determined if the new code adds the business value it was intended to. These two decision points are common through the remainder of these pipeline examples, except single-tenant, which adds some additional ones. The remainder of the pipeline should be automated and without user intervention.
Advantages
- Most bugs can be found before production
- Improved uptime
- Allow for extended feature development without affecting the ability to deploy hotfixes to production
- Some automation
Disadvantages
- Bugs with production data may persist
- Delays of new features in UAT may delay hotfixes
- More environments usually incur more cost
- Lacks advanced testing
- Modestly complex setup
Use Cases
- Systems with modest code change frequency
- Systems with low tolerance for hotfix delays
- Systems where UAT approval is relatively quick
Feature Branches
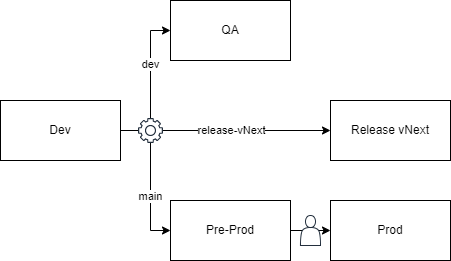
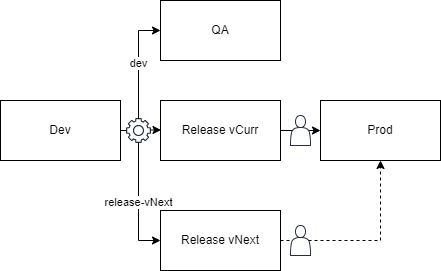
The feature branch approach takes the “basic testing with hotfixes” method to the next level. Now, you create a separate branch for each new product version. This branch can create a release environment that will eventually deploy to your production environment. By using feature branches, the risk of delays in User Acceptance Testing (UAT) causing setbacks for hotfixes is significantly reduced because UAT approval no longer blocks the production environment.
There are several ways to implement feature branch environments, and a couple of examples are illustrated above. The first approach involves creating a release branch that automatically creates a corresponding release environment. UAT for the new features takes place in this release environment. Once the release is ready and approved, the code is merged into the main branch, passed through a Pre-Prod environment, and swiftly deployed into production, leaving Pre-Prod available for hotfixes. The new Pre-Prod environment primarily serves as a final light validation stage before the code goes live in production. Changes should not linger in Pre-Prod before getting pushed to production.
The second approach is a variation where both the current (vCurr) and next (vNext) releases have their own branches and environments. Any hotfixes are applied to the current release branch and environment before getting pushed to production. When the next release is ready, its environment is pushed into production, becoming the new current release. The previous current release’s environment is no longer necessary and can be removed.
Typically, vCurr and vNext represent actual version numbers, such as v1.3 and v1.4.
With the feature branch approach, you’ll likely create and remove environments more frequently. Infrastructure as Code is now necessary instead of just a recommendation for cloud deployments for successful pipeline setups. Also, depending on your approach to creating release branches, having a separate QA environment may not be necessary. Remember that the feature branch approach allows flexibility in deciding when and how to set up your release branches.
I’ll exclude the feature branch from the remaining pipelines for simplicity. However, you can incorporate feature branches into other strategies if needed.
Advantages
- Most bugs can be found before production
- Improved uptime
- Most hotfixes can be deployed with ease
- Significant automation
Disadvantages
- Bugs and deployment problems with production data may persist
- Lacks advanced testing
- Lots of environments
- Complex setup with changing environments
- Moderate maintenance
Use Cases
- Systems with modest code change frequency
- Systems with low tolerance for hotfix delays
Staging Testing
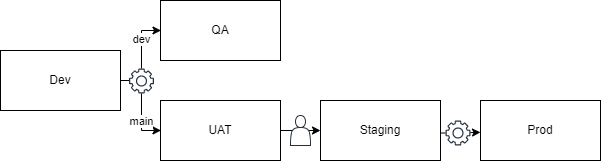
Another valuable addition to your pipeline is the Staging environment. Think of the Staging environment as a replica of your production environment. It should be built similarly, utilizing a backup of your production database. The purpose of the Staging environment is to conduct a series of tests against an environment that is as close to production as possible. This allows you to identify and address any bugs or deployment issues that may only arise in the production environment.
A Staging environment only starts to add significant value after your automated testing reaches a point where you are confident that the system is fully functional if your tests pass. Usually, this requires extensive automated end-to-end tests in addition to your other test suites. While you can establish a Staging environment before that point, doing so doesn’t add much value to your other testing, which can be done in the UAT environment manually. Creating the overhead of the staging environment is usually not worth the extra time and effort without comprehensive automated testing.
If your environments are in Azure and utilize Web Apps or similar services, you can also use slot swapping to reduce downtime and allow for rollback if needed. In slot swapping, you deploy your Staging environment to a slot in your Web App. When your tests pass, you automatically swap your staging slot into production. This ensures your site is warmed up for better availability and response time immediately after deployment. Additionally, if an issue is discovered, the old production, which is now in the staging slot, can be switched back for a quick recovery. More information can be found here. For AWS, Route53 can switch the environments at a DNS level.
Advantages
- Nearly all bugs and deployment problems can be found before production
- Very high uptime
- Most hotfixes can be deployed with ease
- Significant automation
Disadvantages
- Several environments
- Moderate to high maintenance
- Requires robust automated testing
Use Cases
- Systems with frequent code changes
- Systems with very high uptime requirements
Advanced Testing and Deployment
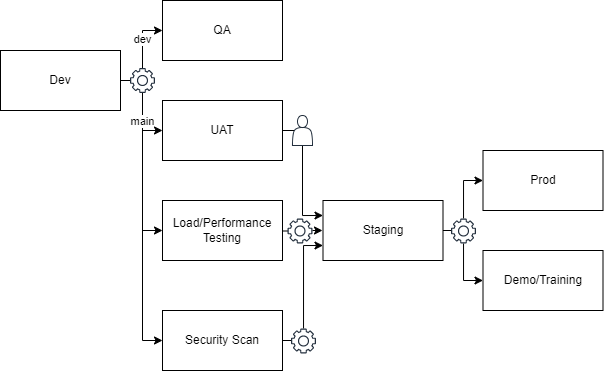
As your system expands, you’ll likely encounter various situations where additional environments become necessary. Load, security, and accessibility testing are common scenarios that often call for extra infrastructure. It’s best to automatically set these new environments up, with tests running without manual intervention. Only when all the tests pass should the changes be allowed to progress to the next deployment stage.
Furthermore, you might find it beneficial to have a demo environment for your sales team or a training environment to facilitate onboarding for new employees. These environments can be created and updated as part of your deployment pipeline, ensuring that your sales staff can showcase the system effectively and newcomers can quickly grasp its functionality.
Adding these environments to your pipeline provides a more comprehensive and feature-rich system.
Advantages
- Nearly all bugs and deployment problems can be found before production
- Very high uptime
- Most hotfixes can be deployed with ease
- Very advanced automated testing
- Extensive automation
Disadvantages
- Lots of environments
- Complex setup with changing environments
- Extensive maintenance
Use Cases
- Systems with extensive security, performance, or other testing requirements
- Systems requiring “alternate production” environments like training or demo
Single-Tenant
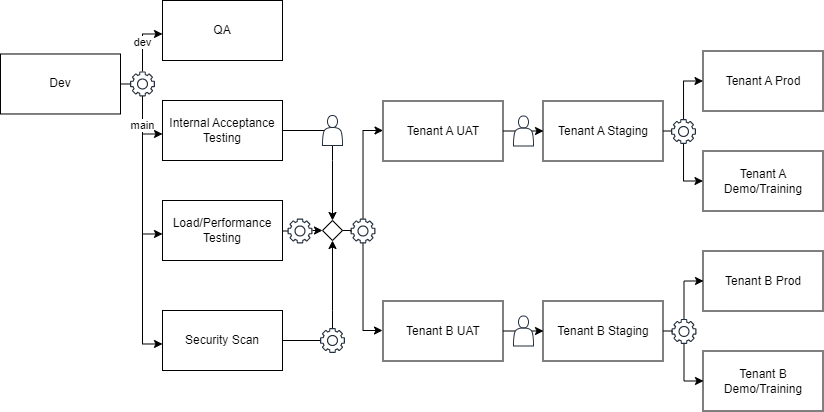
Lastly, let’s address a niche scenario that arises when specific requirements such as white labeling, security, or deployment location demand a single-tenant system. In such cases, we can still accommodate all the advanced environment features discussed earlier, but with a twist. At some stage in the deployment pipeline, typically after completing basic testing, multiple environments are set up, each catering to a specific tenant.
In addition, we’ve incorporated new approval gates as part of the process before the code reaches each tenant’s production environment. This is a commonly employed flexibility in such systems, where tenants require control over deploying code changes to their users. Including these approval gates empowers approvers to manage the rollout according to the tenant’s preferences and enables thorough testing of tenant-specific features that may demand extra attention. It’s a valuable feature that enhances the overall functionality and adaptability of the system.
The single-tenant pipeline is inherently complex, and it’s important to acknowledge that changes will occur frequently. Automating the entire process becomes a crucial prerequisite to navigating this complexity successfully. By automating the setup of tenant-specific environments, we can ensure efficiency and accuracy while accommodating each tenant’s unique needs.
Advantages
- Nearly all bugs and deployment problems can be found before production
- Very high uptime
- Most hotfixes can be deployed with ease
- Very advanced automated testing
- Extensive automation
- Support for multiple unique production environments
Disadvantages
- Lots of environments
- Complex setup with changing environments
- Very extensive maintenance
Use Cases
- Single tenant systems


